A laptop, eight hours, and a 96,715-word vocabulary from random init
A 1.6-million-parameter byte-level transformer, initialised to random
weights with no pretraining of any kind, learned to emit
English-shaped text containing real dictionary words on a single
MacBook in 8 hours of wall-clock training. By the end of the run, one
in five emitted chunks was a real strict-dictionary English word —
content like caste, bones, phonies, logged, dine, ring,
who, try, phoca (a genus of seals) — up from a baseline rate of
4% before training. Total cost: zero dollars and one open laptop.
The point isn’t the model — at this scale and training duration it’s not useful for anything. The point is that the mechanism works: no curated corpus, no labelled data, no API calls, no cloud, no distillation from a frontier model. Just a small transformer playing a turn-taking word-emission game against a dictionary-sampling “teacher,” with a WordNet-grounded verifier deciding what counts as real, and an adaptive curriculum that lifted the difficulty as mastery emerged.
It’s a probe of a load-bearing assumption underneath a much bigger architectural picture for tabula-rasa LLM bootstrapping. The probe held.
What it actually did
The pupil starts at random weights. There’s nothing in it. Its first emissions look like uniform random bytes — about 20% of them are letters by chance, the rest are arbitrary.
A teacher (a fast dictionary sampler driven by an adaptive curriculum) emits a word each turn. The pupil trains to predict the teacher’s next emission given the previous word — standard next-byte cross-entropy. Then the pupil samples its own word; a verifier (WordNet synset + length ≥ 3) decides whether it’s real; and a REINFORCE-style gradient nudges the pupil toward emissions that scored. Both losses run on every iteration. The curriculum has six levels — 1-letter words → 2-letter → 3-letter → 4–5 letter → 6–8 letter → full strict dictionary — and advances automatically when the focus level’s recent success rate clears its (per-level) threshold.
Eight hours later, the pupil has worked its way through every level. The final hour’s emissions look like this:
shepaws sinds ppos arn f chiatalel ctics meine p ps mes rices
rinalinon ricasa try phoca gona lonary phetin on ches ehes lininin
That’s babble — but it’s English-shaped babble with real words
embedded. The non-words have English prosody (shepaws, chiatalel,
rinalinon, phetin); the real words land naturally in the stream
(arn, mes, rices, try, phoca, gona, on).
Numbers
- Compute: M2 Max MacBook Pro, 96 GB unified memory. No GPU beyond the M-series. MLX framework.
- Model: byte-level decoder-only transformer. 4 layers, 256 hidden dim, 4 heads, 128-byte context window. ~1.6 M parameters. Random init.
- Training time: 28 800 s wall-clock (8 h 0 m 19 s including trace sampling overhead).
- Final
%dict(strict WordNet verifier, length ≥ 3): 0.21. Untrained baseline: ~0.04. - Final
%letters: 0.78 (of emitted bytes are alphabetic). - Final
%shape(letter-runs of plausible word length 3–12): 0.60. - Loss EMA: 2.43 → 1.97 over the 8 hours.
- Working vocabulary at end of run: the full strict-verifier dictionary, 96 715 words. The model isn’t fluent over it — final per-level success rate at L5 is 21% — but it’s exposed to and scored against the whole list.
The headline plot:
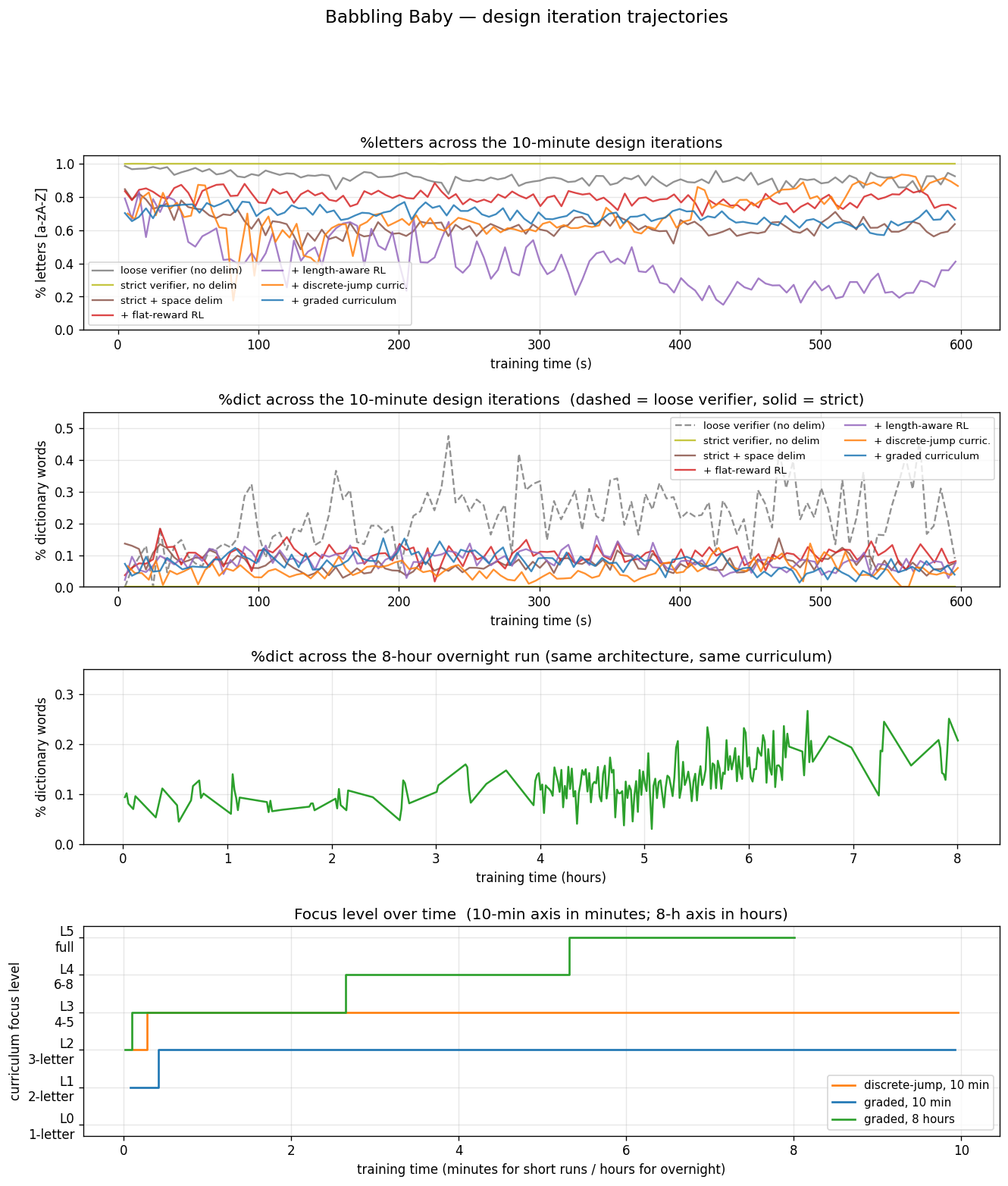
Top panel: %letters across the seven 10-minute design iterations.
Second: %dict across the same iterations. Third: the 8-hour
overnight %dict trajectory. Bottom: focus level over time for the
three curriculum-driven runs, with x-axes in minutes for the short
runs and hours for the long one.
Why this is interesting
The dominant paradigm for building language models is pretraining on massive curated corpora, in well-resourced labs, with compute budgets that range from “expensive” to “national-priority.” This experiment is the opposite: tiny model, no corpus, no lab, one laptop, overnight.
It works because the signal the model is learning from isn’t a static corpus — it’s the behaviour of an entity that emits real words, plus a grounded verifier that says yes-or-no without human judgement. The pupil is bootstrapped by playing against this behaviour, in the same way AlphaZero bootstraps by playing against itself with a win/loss verifier.
The broader architectural picture that motivated the experiment is described elsewhere; the short version is that prediction of intelligent behaviour, paired with grounded verifiers, may be a viable substrate for cumulative learning without centralised pretraining. The narrow claim under test in this experiment is the load-bearing one: that prediction-plus-verifier can drive a randomly-initialised model to anything meaningful on commodity hardware.
It can. That’s what’s interesting.
The seven dead ends and the breakthrough
The 8-hour result is what happens when you set the system loose with the right design. Most of the experimental day was spent finding the right design. Here’s the chronology, with the cross-run plot above as backdrop:
Run 1 — loose verifier, no delimiter. First attempt. A
pyspellchecker-only verifier (no WordNet filter) credited 47% peak
%dict. Looked great until inspection: most of the “dictionary
hits” were two- and three-letter fragments like se, ss, st,
sm that the wordlist included as abbreviations and initialisms.
Not real words by any human standard.
Run 2 — strict verifier, no delimiter. Switched the verifier to
require both length ≥ 3 and a WordNet synset. %dict collapsed to
zero across the entire 10-minute run. The trace metric was
honest now, and what it honestly said was that the model had no real
word boundaries in its output. The filtered wordlist removed
possessive forms (cat's), and those apostrophes had been the
accidental boundary signal in run 1. Run 1’s 47% was bigram noise
between apostrophes.
Run 3 — explicit space delimiter. Added a space byte at the end
of every teacher emission. The pupil now had boundaries in its
training data. %dict reached 15% peak, but the model mode-collapsed
to emitting short fragments separated by lots of spaces.
Run 4 — flat-reward RL. Added the verifier as an RL signal:
+1 for hits, −0.1 for misses. %dict peaked at 18%. 223 unique real
words emitted across the run. Marginal improvement.
Run 5 — length-aware reward. Made the penalty scale with how far
the emission’s length was from the teacher’s typical word length —
short fragments get punished harder. Result was worse. The model
retreated from emitting letters at all; %letters dropped to 41%.
The harsh penalty regime taught the model to stop committing to
words; the imitation signal kept it on rails but barely.
Run 6 — discrete-jump curriculum. Added a six-level length-progressive curriculum with a flat 30% promotion threshold. The model graduated through L0–L3 (1-letter through 4–5 letter words) in 14 seconds, then stalled at L3 because the success rate never quite crossed 30%. 179 unique real words emitted.
Run 7 — graded curriculum with overlapping levels. Replaced the discrete-jump promotion with per-level thresholds (0.85, 0.65, 0.45, 0.30, 0.20, 0.10) and a mixture sampling regime where the teacher emitted from focus ± 1 each turn (70%/20%/10%). The model now had to master each level before moving on — and got early exposure to the next one. In 10 minutes it only reached L2, but emitted 251 unique real words, the most yet, and the L2 success rate was climbing toward 0.45 in a clean trajectory.
Run 8 — overnight at 8 hours, same graded curriculum. Given time, the curriculum did its job. L2 mastered in 26 seconds. L3 by 3 minutes. L4 took 2 h 24 m. L5 took another 2 h 54 m. By 5 h 18 m the model was working against the full strict dictionary; by 8 h it was emitting real words at 21% rate and unique-real-word count had climbed to 402.
The pattern across the iterations is the same: each failure was diagnostic, and the diagnosis pointed at the next constraint. The graded curriculum is the version that made the whole pipeline coherent — strict verifier + delimiter + positive-only RL + per-level mastery thresholds.
How long does each level cost?
For the graded curriculum overnight:
| transition | wall-clock | gap from previous |
|---|---|---|
| → L1 (2-letter) | 1.7 s | 1.7 s |
| → L2 (3-letter) | 26.5 s | 25 s |
| → L3 (4–5 letter) | 3 m 5 s | 2 m 38 s |
| → L4 (6–8 letter) | 2 h 24 m | 2 h 22 m |
| → L5 (full strict) | 5 h 18 m | 2 h 54 m |
| end at L5 | 8 h | 2 h 41 m |
The first three transitions are roughly logarithmic in the vocabulary size of the next level (2 words → 25 words → 775 strict 3-letter words). After that, every transition costs about 2.5 hours of training. That’s the empirical compute curve for this architecture at this scale, at this training rate. A bigger model would presumably have shorter curves; an even smaller one, longer. Nobody has tried.
What got built
A Python package with six modules, 57 tests, and ~600 lines of code besides tests. The architecture is intentionally minimal: nothing in here is novel. Byte-level transformer, REINFORCE, AdamW. The system is what’s novel — the combination of strict WordNet verifier, space-delimited turn-taking game, dictionary teacher, graded length-based curriculum, and positive-only RL signal.
src/babbling_baby/
├── verifier.py # is_word: length≥3 AND WordNet synset
├── teacher.py # DictionaryTeacher driven by curriculum
├── pupil.py # byte-level decoder transformer + sampling
├── curriculum.py # adaptive graded with per-level thresholds
├── trace.py # %printable / %letters / %shape / %dict metrics
└── train.py # interactive imitation + verifier-RL loop
The whole experiment is on GitHub at
elepedus/babbling-baby.
The DraftLang spec at
babbling-baby.draft.md
captures the guarantees the system promises; the
README.md
gives the engineering-level account; this post is the journalistic
one.
What this doesn’t mean
It doesn’t mean the broader architecture (multi-teacher, peer challenge, architecture evolution, environment grounding) works — none of those were tested. It doesn’t mean small from-scratch models will out-compete pretrained giants — they won’t, at this scale.
It also doesn’t mean the paradigm is competitive with pretraining. Pretraining absorbs the entire web in days of distributed training and produces models that can write essays. This pupil, after 8 hours, emits dictionary-shaped babble with real words sprinkled through. The comparison isn’t even close.
What it does mean is that the load-bearing assumption underneath the broader paradigm — that a random-initialised byte-level model can be brought to meaningful structured output by prediction signal plus a grounded verifier alone, on commodity hardware — is empirically supported. That’s a step, not a paradigm shift.
What v1 might test
The architectural picture this experiment lives inside has substantial untested surface area. In rough order of how sharply each candidate probes the next open claim:
- Batched and population training. A quick benchmark shows the GPU was running at ~1–2% utilisation during the overnight run. At batch size 1 the M2 Max processes 195 examples/sec; at batch size 64 it processes 8 100/sec (41× more) for only 1.5× more wall-clock per step. Two consequences: (i) the 8-hour run could plausibly become a 10–20 minute run at batch size 64 with no architectural change, and (ii) population training becomes real — stack N pupils’ parameters into a single batched tensor, vmap the forward, train an entire population in one forward pass. The cheapest first move on any of the v1 candidates below would be to exploit this headroom first.
- Bigger model + longer training. Does
%dictkeep climbing past 21% with more capacity and more time? At what model size does each level transition stop costing hours? (Combined with batched training, the answer to “more time” is much cheaper than it looks.) - Architecture variant: diffusion–AR hybrid (TiDAR). Nvidia’s TiDAR paper (Liu et al., Think in Diffusion, Talk in Autoregression, 2025) introduces a hybrid architecture that combines diffusion-style parallel drafting with AR-quality sampling in a single forward pass, via structured attention masks: prefix tokens attend causally, mask tokens within each block attend bidirectionally, and the model both drafts (diffusion mode) and samples (AR mode) in one forward. At 1.5B–8B scales the speedup is 4.71×–5.91× over pure AR with no quality loss. The recipe is data-efficient; adapting it to the byte-level pupil would be straightforward architecturally — same curriculum, same verifier, new attention masks plus the dual-mode loss. Open questions: does the diffusion component change what the pupil can learn or just how fast? Does parallel drafting destabilise the imitation signal the graded curriculum depends on? And — most interestingly in combination with the multimodality entry below — byte-level inputs + diffusion-style parallel output is intriguing for image generation, since images (as raw pixel bytes or post-decode PNG) are naturally parallel outputs and diffusion powers nearly every successful image generator. Whether byte-level diffusion generalises to images — rather than the latent-space diffusion that dominates the field — is a real open question this combination could probe.
- Phrase-level curriculum. Same mechanism, longer units. The
current curriculum stops at single words; extend it to grammatical
fragments of increasing complexity:
Cat sat.→Man fell.→Three blind mice.→The cat sat on the mat.The verifier becomes a grammaticality check rather than dictionary lookup — could be a small parser, a syntactic checker, or an LM-based is this well-formed English? gate. Tests whether the same prediction-plus-verifier regime extends from lexical into syntactic structure, and whether the same graded-curriculum pedagogy generalises across levels of linguistic granularity. - Multimodality and cross-modal equivalence. The byte-level
substrate was chosen partly because bytes are universal across
modalities. The natural extension is to train the same
architecture independently on text bytes, audio bytes (raw PCM
or codec output), and image bytes (PNG/JPEG, or pixel arrays),
and then on mixed streams. The strongest version of the test:
can the model learn the equivalence between modalities —
audio of “cat” maps to text
catmaps to an image of a cat — purely from prediction over their interleaved byte streams? Same prediction objective, no modality-specific loss terms. If it works, the substrate generalises to multimodal grounding without a different training regime. - Multi-teacher prediction. Add Claude or a local LLM alongside the dictionary sampler. Does the pupil acquire structure that no single teacher could provide alone? Does the prediction objective survive across heterogeneous teachers?
- Anticipation rather than imitation. Train on predicting the teacher’s next emission given trace prefix rather than completing the current one. Does that produce qualitatively different learning?
- Peer challenge. Two pupils, each posing hard problems to the other. Does the convergence dynamic the AlphaZero analogy implies actually work at this scale?
- VM embodiment. A pupil acting in a sandboxed Linux container, with the verifier checking program output instead of dictionary membership. Does grounding in real action-and-consequence shift what gets learned, vs. learning from textual surfaces alone?
The point isn’t to do all of them; it’s to pick the one that sharpens the next claim under test.
Reproducing it
git clone https://github.com/elepedus/babbling-baby.git
cd babbling-baby
uv sync --extra dev
uv run python scripts/run_training.py 600 5 # 10 minutes
uv run python scripts/run_training.py 28800 60 # 8 hours
uv run python scripts/plot_trace.py runs/<id>/trace.jsonl
uv run python scripts/plot_journey.py # cross-run comparison
Each run produces a runs/<timestamp>/ directory with trace.jsonl,
levels.jsonl, pupil.npz (the saved model weights), and a
trace.png. On an M2 Max, the 10-minute runs finish in 10 minutes
and the 8-hour run in 8 hours. No surprises.
The saved overnight model (runs/20260526-220809/pupil.npz,
~13 MB) is the artefact this experiment produced — and the seed
state for whichever v1 test happens next.